
De Segmentos a Escenas: Comprensión Temporal en Conducción Autónoma
Conoce el benchmark TAD para conducción autónoma. Scene-CoT y TCogMap mejoran la comprensión temporal de VLMs hasta un 17.72% sin entrenamiento.
Conoce el benchmark TAD para conducción autónoma. Scene-CoT y TCogMap mejoran la comprensión temporal de VLMs hasta un 17.72% sin entrenamiento.

VLM4VLA revela que la capacidad general de los VLM no garantiza un buen control robótico. Descubre las claves para elegir el modelo adecuado.

Descubre cómo LASER logra una aceleración 2.3x en modelos visión-lenguaje con baja precisión, usando SVD consciente de pérdida y asignación de rango.
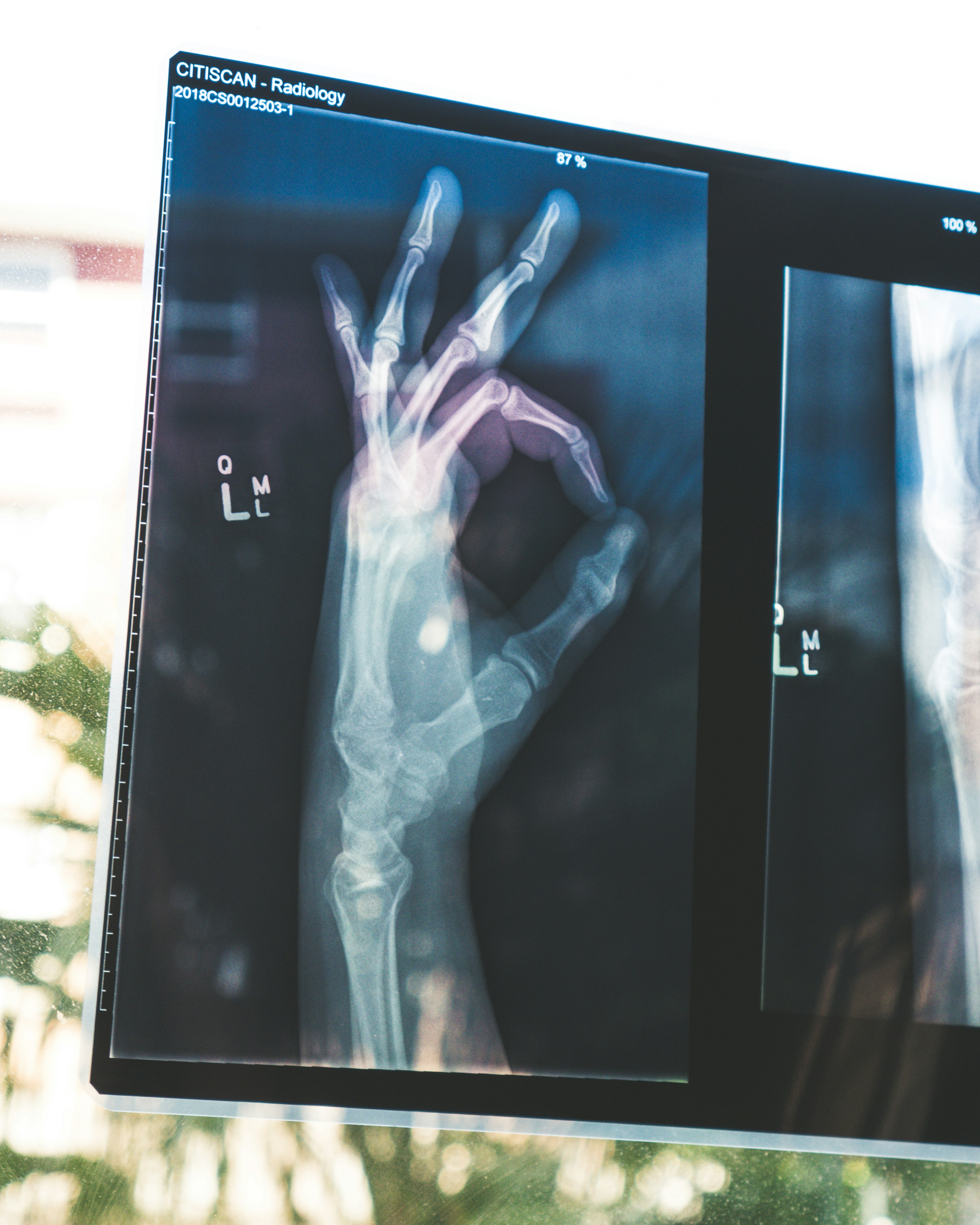
Los modelos de IA clínica pueden reidentificar pacientes al vincular radiografías con informes. Descubre cómo la privacidad diferencial reduce este riesgo.

Descubre cómo ComProScanner extrae datos de materiales de figuras científicas con precisión del 97%. Automatiza tu investigación.

STaR-KV comprime la caché KV en modelos GUI sin entrenamiento, reduciendo memoria GPU un 40% sin penalizar precisión. Descubre cómo.
¿Los VLMs saben cuándo abstenerse? Un estudio revela que fallan en preguntas espaciales con oclusión o ambigüedad, respondiendo con exceso de confianza. Descubre por qué.

CMAC: un método sin entrenamiento que calibra la atención cross-modal para mitigar alucinaciones en LVLMs. Corrige sesgos y mejora la consistencia visual-textual.

Descubre cómo el Adaptador Variacional mejora la similitud multimodal resolviendo falsos negativos y potenciando la generalización en modelos de visión-lenguaje

El colapso de plantillas limita la detección de hallazgos críticos en TC 3D. Conoce CLarGen, el método que separa detección de síntesis para informes más precisos.

Aprende cómo FOCUS localiza objetos en contexto sin supervisión de categorías, usando apoyo visual y optimización por refuerzo. Supera modelos de hasta 72B parámetros.

Descubre cómo el enrutamiento dinámico de adaptadores mejora la recuperación multimodal continua, superando métodos tradicionales. Ideal para IA y visión.
<meta name=description content=Evaluación de modelos de visión-lenguaje para la indexación de picos XRD. Descubre los resultados y su precisión en el análisis de difracción de rayos X.>
Comparativa de modelos visión-lenguaje en CFMME, dataset multimodal financiero chino. Análisis de rendimiento y aplicaciones en finanzas.
Análisis del cuello de botella del conteo visual en modelos de visión-lenguaje: limitaciones actuales y perspectivas para mejorar la precisión en tareas numéricas.
<meta content=Descubre el ajuste federado de prompts multietiqueta para optimizar modelos visión-lenguaje con aprendizaje distribuido y eficiente>